---
title: "deepseek-r1"
publisher: "deepseek-ai"
type: "endpoint"
updated: "2025-07-17T04:37:42.998Z"
description: "State-of-the-art, high-efficiency LLM excelling in reasoning, math, and coding."
canonical: "https://build.nvidia.com/deepseek-ai/deepseek-r1"
---
**Model Overview**
## Description:
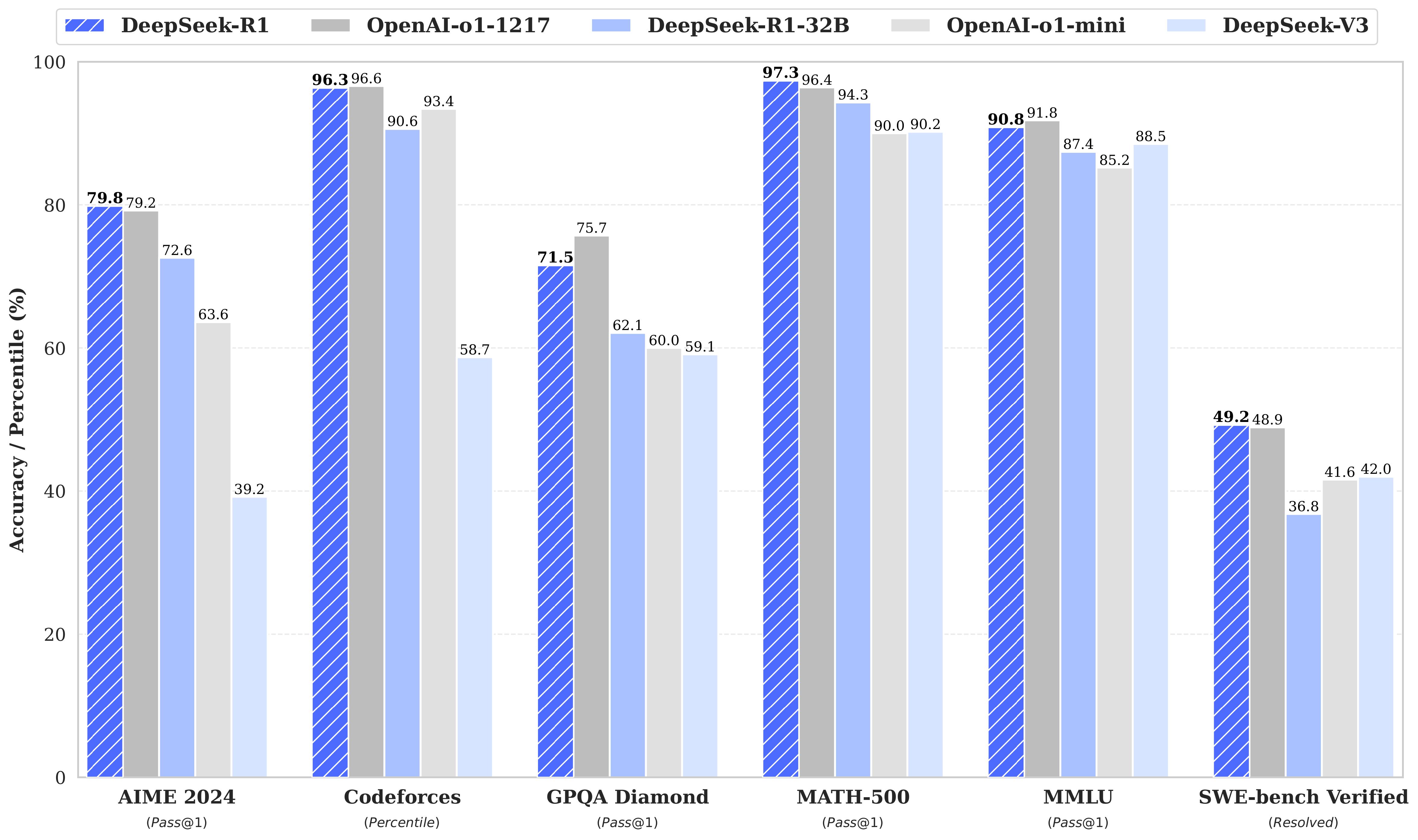
DeepSeek-R1 is a first-generation reasoning model trained using large-scale reinforcement learning (RL) to solve complex reasoning tasks across domains such as math, code, and language. The model leverages RL to develop reasoning capabilities, which are further enhanced through supervised fine-tuning (SFT) to improve readability and coherence. DeepSeek-R1 achieves state-of-the-art results in various benchmarks and offers both its base models and distilled versions for community use.
This model is ready for both research and commercial use.
For more details, visit the [DeepSeek website](https://www.deepseek.com/).
## Third-Party Community Consideration:
This model is not owned or developed by NVIDIA. It is a community-driven model created by DeepSeek AI. See the official [DeepSeek-R1 Model Card](https://huggingface.co/deepseek-ai/DeepSeek-R1) on Hugging Face for further details.
## License/Terms of Use:
GOVERNING TERMS: This trial service is governed by the [NVIDIA API Trial Terms of Service](https://assets.ngc.nvidia.com/products/api-catalog/legal/NVIDIA%20API%20Trial%20Terms%20of%20Service.pdf). Use of this model is governed by the [NVIDIA Community Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-community-models-license/). Additional Information: [MIT License](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/mit.md).
## References:
- [DeepSeek GitHub Repository](https://github.com/deepseek-ai/DeepSeek-R1)
- [DeepSeek-R1 Paper](https://arxiv.org/abs/2501.12948)
## Model Architecture:
**Architecture Type:** Mixture of Experts (MoE)
**Network Architecture:**
- Base Model: DeepSeek-V3-Base
- Activated Parameters: 37 billion
- Total Parameters: 671 billion
- Distilled Models: Smaller, fine-tuned versions based on Qwen and Llama architectures.
- Context Length: 128K tokens
## Input:
**Input Type(s):** Text
**Input Format(s):** String
**Input Parameters:** (1D)
**Other Properties Related to Input:**
DeepSeek recommends adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:
1. Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
2. **Avoid adding a system prompt; all instructions should be contained within the user prompt.**
3. For mathematical problems, it is advisable to include a directive in your prompt such as: "Please reason step by step, and put your final answer within \boxed{}."
4. When evaluating model performance, it is recommended to conduct multiple tests and average the results.
## Output:
**Output Type(s):** Text
**Output Format:** String
**Output Parameters:** (1D)
## Software Integration:
**Runtime Engine(s):** vLLM and SGLang
**Supported Hardware Microarchitecture Compatibility:** NVIDIA Ampere, NVIDIA Blackwell, NVIDIA Jetson, NVIDIA Hopper, NVIDIA Lovelace, NVIDIA Pascal, NVIDIA Turing, and NVIDIA Volta architectures
**[Preferred/Supported] Operating System(s):** Linux
## Model Version(s):
DeepSeek-R1 V1.0
## Training, Testing, and Evaluation Datasets:
### Training Dataset:
**Data Collection Method by dataset:** Hybrid: Human, Automated
**Labeling Method by dataset:** Hybrid: Human, Automated
### Testing Dataset:
**Data Collection Method by dataset:** Hybrid: Human, Automated
**Labeling Method by dataset:** Hybrid: Human, Automated
### Evaluation Dataset:
**Data Collection Method by dataset:** Hybrid: Human, Automated
**Labeling Method by dataset:** Hybrid: Human, Automated
## Inference:
**Engine:** SGLang
**Test Hardware:** NVIDIA Hopper
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse. Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Model Limitations:
The base model was trained on data that contains toxic language and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.
## Prototype
```python
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$NVIDIA_API_KEY"
)
completion = client.chat.completions.create(
model="",
messages=[{"role":"user","content":""}],
temperature=,
top_p=,
max_tokens=,
stream=NaN
)
reasoning = getattr(completion.choices[0].message, "reasoning_content", None)
if reasoning:
print(reasoning)
print(completion.choices[0].message.content)
```
```python
from langchain_nvidia_ai_endpoints import ChatNVIDIA
client = ChatNVIDIA(
model="",
api_key="$NVIDIA_API_KEY",
temperature=,
top_p=,
max_tokens=,
)
response = client.invoke([{"role":"user","content":""}])
if response.additional_kwargs and "reasoning_content" in response.additional_kwargs:
print(response.additional_kwargs["reasoning_content"])
print(response.content)
```
```javascript
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: '$NVIDIA_API_KEY',
baseURL: 'https://integrate.api.nvidia.com/v1',
})
async function main() {
const completion = await openai.chat.completions.create({
model: "",
messages: [{"role":"user","content":""}],
temperature: ,
top_p: ,
max_tokens: ,
stream:
})
const reasoning = completion.choices[0]?.message?.reasoning_content;
if (reasoning) process.stdout.write(reasoning + "\n");
process.stdout.write(completion.choices[0]?.message?.content);
}
main();
```
```bash
invoke_url='https://integrate.api.nvidia.com/v1/chat/completions'
authorization_header='Authorization: Bearer '
accept_header='Accept: application/json'
content_type_header='Content-Type: application/json'
data=$'{
"messages": [
{
"role": "user",
"content": ""
}
]
}'
response=$(curl --silent -i -w "\n%{http_code}" --request POST \
--url "$invoke_url" \
--header "$authorization_header" \
--header "$accept_header" \
--header "$content_type_header" \
--data "$data"
)
echo "$response"
```