---
title: "llama-3.3-nemotron-super-49b-v1.5"
publisher: "nvidia"
type: "endpoint"
updated: "2025-07-25T23:06:24.458Z"
description: "High efficiency model with leading accuracy for reasoning, tool calling, chat, and instruction following."
canonical: "https://build.nvidia.com/nvidia/llama-3_3-nemotron-super-49b-v1_5"
---
# Llama-3.3-Nemotron-Super-49B-v1.5
## Model Overview
Llama-3.3-Nemotron-Super-49B-v1.5 is a significantly upgraded version of Llama-3.3-Nemotron-Super-49B-v1 and is a large language model (LLM) which is a derivative of Meta Llama-3.3-70B-Instruct (AKA the reference model). It is a reasoning model that is post trained for reasoning, human chat preferences, and agentic tasks, such as RAG and tool calling. The model supports a context length of 128K tokens.
Llama-3.3-Nemotron-Super-49B-v1.5 is a model which offers a great tradeoff between model accuracy and efficiency. Efficiency (throughput) directly translates to savings. Using a novel Neural Architecture Search (NAS) approach, we greatly reduce the model’s memory footprint, enabling larger workloads, as well as fitting the model on a single GPU at high workloads (H200). This NAS approach enables the selection of a desired point in the accuracy-efficiency tradeoff. For more information on the NAS approach, please refer to [this paper](https://arxiv.org/abs/2411.19146)
The model underwent a multi-phase post-training process to enhance both its reasoning and non-reasoning capabilities. This includes a supervised fine-tuning stage for Math, Code, Science, and Tool Calling. Additionally, the model went through multiple stages of Reinforcement Learning (RL) including Reward-aware Preference Optimization (RPO) for chat, Reinforcement Learning with Verifiable Rewards (RLVR) for reasoning, and iterative Direct Preference Optimization (DPO) for Tool Calling capability enhancements. The final checkpoint was achieved after merging several RL and DPO checkpoints.
This model is part of the Llama Nemotron Collection. You can find the other model(s) in this family here:
- [Llama-3.1-Nemotron-Nano-4B-v1.1](https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1)
- [Llama-3.1-Nemotron-Ultra-253B-v1](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1)
This model is ready for commercial use.
## License/Terms of Use
GOVERNING TERMS: The trial service is governed by the [NVIDIA API Trial Terms of Service](https://assets.ngc.nvidia.com/products/api-catalog/legal/NVIDIA%20API%20Trial%20Terms%20of%20Service.pdf); and the use of this model is governed by the [NVIDIA Open Model License.](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) Additional Information: [Llama 3.3 Community License Agreement](https://www.llama.com/llama3_3/license/). Built with Llama.
**Model Developer:** NVIDIA
**Model Dates:** Trained between November 2024 and July 2025
**Data Freshness:** The pretraining data has a cutoff of 2023 per Meta Llama 3.3 70B
## Deployment Geography
Global
### Use Case:
Developers designing AI Agent systems, chatbots, RAG systems, and other AI-powered applications. Also suitable for typical instruction-following tasks.
### Release Date:
- Hugging Face 7/25/2025 via [Llama-3_3-Nemotron-Super-49B-v1_5](https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5)
- build.nvidia.com 7/25/2025 [Llama-3_3-Nemotron-Super-49B-v1_5](https://build.nvidia.com/nvidia/llama-3_3-nemotron-super-49b-v1_5)
## References
* [\[2505.00949\] Llama-Nemotron: Efficient Reasoning Models](https://arxiv.org/abs/2505.00949)
* [\[2502.00203\] Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment](https://arxiv.org/abs/2502.00203)
* [\[2411.19146\]Puzzle: Distillation-Based NAS for Inference-Optimized LLMs](https://arxiv.org/abs/2411.19146)
## Model Architecture
**Architecture Type:** Dense decoder-only Transformer model
**Network Architecture:** Llama 3.3 70B Instruct, customized through Neural Architecture Search (NAS)
The model is a derivative of Meta’s Llama-3.3-70B-Instruct, using Neural Architecture Search (NAS). The NAS algorithm results in non-standard and non-repetitive blocks. This includes the following:
Skip attention: In some blocks, the attention is skipped entirely, or replaced with a single linear layer.
Variable FFN: The expansion/compression ratio in the FFN layer is different between blocks.
We utilize a block-wise distillation of the reference model, where for each block we create multiple variants providing different tradeoffs of quality vs. computational complexity, discussed in more depth below. We then search over the blocks to create a model which meets the required throughput and memory (optimized for a single H100-80GB GPU) while minimizing the quality degradation. The model then undergoes knowledge distillation (KD), with a focus on English single and multi-turn chat use-cases. The KD step included 40 billion tokens consisting of a mixture of 3 datasets - FineWeb, Buzz-V1.2 and Dolma.
## Intended use
Llama-3.3-Nemotron-Super-49B-v1.5 is a general purpose reasoning and chat model intended to be used in English and coding languages. Other non-English languages (German, French, Italian, Portuguese, Hindi, Spanish, and Thai) are also supported.
## Input
- **Input Type:** Text
- **Input Format:** String
- **Input Parameters:** One-Dimensional (1D)
- **Other Properties Related to Input:** Context length up to 131,072 tokens
## Output
- **Output Type:** Text
- **Output Format:** String
- **Output Parameters:** One-Dimensional (1D)
- **Other Properties Related to Output:** Context length up to 131,072 tokens
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
## Model Version
1.5 (07/25/2025)
## Software Integration
- **Runtime Engine:** Transformers
- **Recommended Hardware Microarchitecture Compatibility:**
- NVIDIA Ampere
- NVIDIA Hopper
- **Preferred Operating System(s):** Linux
## Quick Start and Usage Recommendations:
1. By default (empty system prompt) the model will respond in reasoning ON mode. Setting `/no_think` in the system prompt will enable reasoning OFF mode.
2. We recommend setting temperature to `0.6`, and Top P to `0.95` for Reasoning ON mode
3. We recommend using greedy decoding for Reasoning OFF mode
You can try this model out through the preview API, using this link: [Llama-3_3-Nemotron-Super-49B-v1_5](https://build.nvidia.com/nvidia/llama-3_3-nemotron-super-49b-v1_5).
## Use It with vLLM
```pip install vllm==0.9.2```
An example on how to serve with vLLM:
```console
$ python3 -m vllm.entrypoints.openai.api_server \
--model "nvidia/Llama-3_3-Nemotron-Super-49B-v1_5" \
--trust-remote-code \
--seed=1 \
--host="0.0.0.0" \
--port=5000 \
--served-model-name "Llama-3_3-Nemotron-Super-49B-v1_5" \
--tensor-parallel-size=8 \
--max-model-len=65536 \
--gpu-memory-utilization 0.95 \
--enforce-eager
```
### Running a vLLM Server with Tool-call Support
To enable tool calling usage with this model, we provide a tool parser in the repository. Here is an example on how to use it:
```console
$ git clone https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5
$ conda create -n vllm python=3.12 -y
$ conda activate vllm
$ pip install vllm==0.9.2
$ python3 -m vllm.entrypoints.openai.api_server \
--model Llama-3_3-Nemotron-Super-49B-v1_5 \
--trust-remote-code \
--seed=1 \
--host="0.0.0.0" \
--port=5000 \
--served-model-name "Llama-3_3-Nemotron-Super-49B-v1_5" \
--tensor-parallel-size=8 \
--max-model-len=65536 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--enable-auto-tool-choice \
--tool-parser-plugin "Llama-3_3-Nemotron-Super-49B-v1_5/llama_nemotron_toolcall_parser_no_streaming.py" \
--tool-call-parser "llama_nemotron_json"
```
After launching a vLLM server, you can call the server with tool-call support using a Python script like below.
```python
from openai import OpenAI
client = OpenAI(
base_url="http://0.0.0.0:5000/v1",
api_key="dummy",
)
completion = client.chat.completions.create(
model="Llama-3_3-Nemotron-Super-49B-v1_5",
messages=[
{"role": "system", "content": ""},
{"role": "user", "content": "My bill is $100. What will be the amount for 18% tip?"}
],
tools=[
{
"type": "function",
"function": {
"name": "calculate_tip",
"parameters": {
"type": "object",
"properties": {
"bill_total": {
"type": "integer",
"description": "The total amount of the bill"
},
"tip_percentage": {
"type": "integer",
"description": "The percentage of tip to be applied"
}
},
"required": ["bill_total", "tip_percentage"]
}
}
},
{
"type": "function",
"function": {
"name": "convert_currency",
"parameters": {
"type": "object",
"properties": {
"amount": {
"type": "integer",
"description": "The amount to be converted"
},
"from_currency": {
"type": "string",
"description": "The currency code to convert from"
},
"to_currency": {
"type": "string",
"description": "The currency code to convert to"
}
},
"required": ["from_currency", "amount", "to_currency"]
}
}
}
],
temperature=0.6,
top_p=0.95,
max_tokens=32768,
stream=False
)
print(completion.choices[0].message.content)
'''
Okay, let's see. The user has a bill of $100 and wants to know the amount for an 18% tip. Hmm, I need to calculate the tip based on the bill total and the percentage. The tools provided include calculate_tip, which takes bill_total and tip_percentage as parameters. So the bill_total here is 100, and the tip_percentage is 18. I should call the calculate_tip function with these values. Wait, do I need to check if the parameters are integers? The bill is $100, which is an integer, and 18% is also an integer. So that fits the function's requirements. I don't need to convert any currency here because the user is asking about a tip in the same currency. So the correct tool to use is calculate_tip with those parameters.
'''
print(completion.choices[0].message.tool_calls)
'''
[ChatCompletionMessageToolCall(id='chatcmpl-tool-e341c6954d2c48c2a0e9071c7bdefd8b', function=Function(arguments='{"bill_total": 100, "tip_percentage": 18}', name='calculate_tip'), type='function')]
'''
```
## Training and Evaluation Datasets
## Training Datasets
A large variety of training data was used for the knowledge distillation phase before post-training pipeline, 3 of which included: FineWeb, Buzz-V1.2, and Dolma.
The data for the multi-stage post-training phases for improvements in Code, Math, and Reasoning is a compilation of SFT and RL data that supports improvements of math, code, general reasoning, and instruction following capabilities of the original Llama instruct model.
Prompts have been sourced from either public and open corpus or synthetically generated. Responses were synthetically generated by a variety of models, with some prompts containing responses for both reasoning on and off modes, to train the model to distinguish between two modes.
NVIDIA will be releasing the post-training dataset in the coming weeks.
**Data Collection for Training Datasets:**
Hybrid: Automated, Human, Synthetic
**Data Labeling for Training Datasets:**
Hybrid: Automated, Human, Synthetic
## Evaluation Datasets
We used the datasets listed below to evaluate Llama-3.3-Nemotron-Super-49B-v1.5.
Data Collection for Evaluation Datasets:
- Hybrid: Human. Synthetic
Data Labeling for Evaluation Datasets:
- Hybrid: Human, Synthetic, Automatic
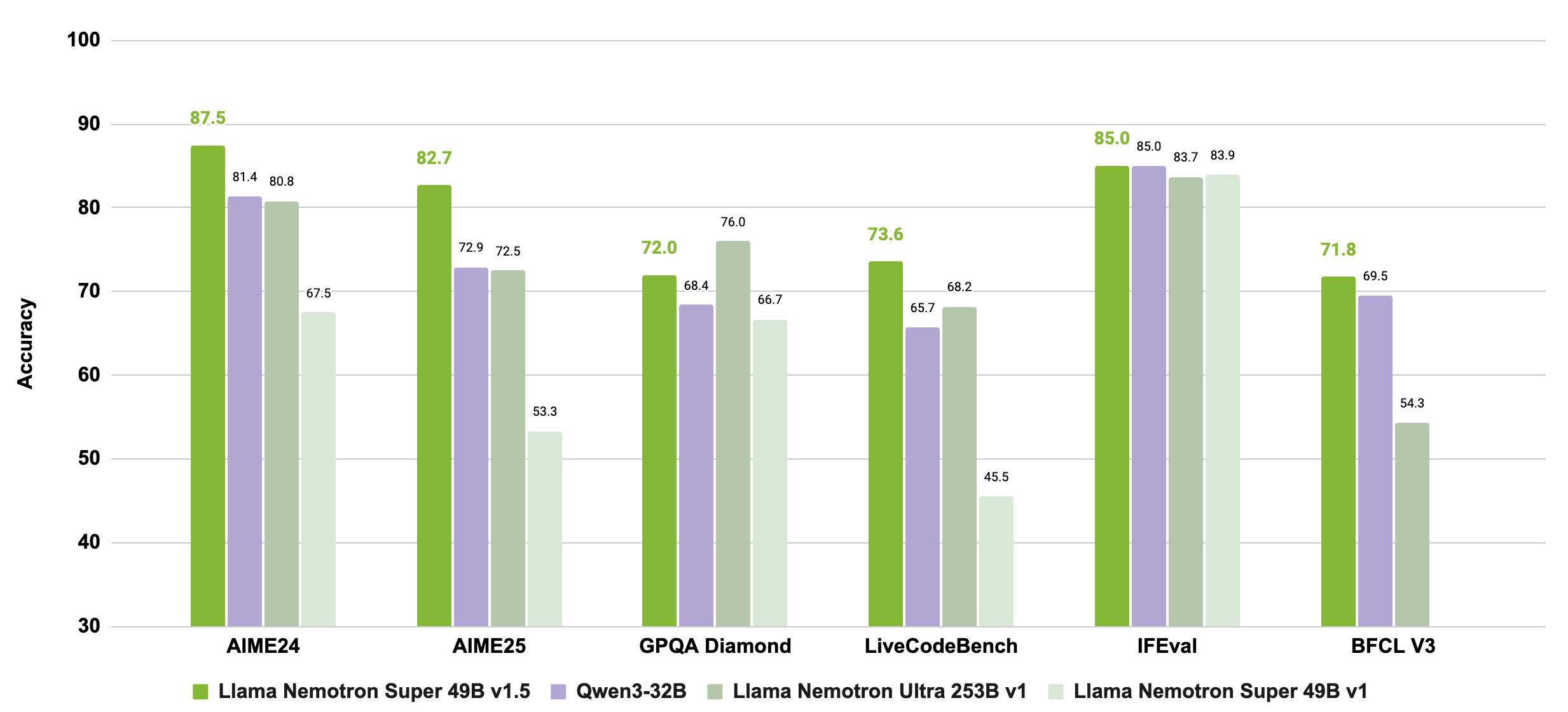
## Evaluation Results
We evaluate the model using temperature=`0.6`, top_p=`0.95`, and 64k sequence length. We run the benchmarks up to 16 times and average the scores to be more accurate.
### MATH500
| Reasoning Mode | pass@1 (avg. over 4 runs) |
|--------------|------------|
| Reasoning On | 97.4 |
### AIME 2024
| Reasoning Mode | pass@1 (avg. over 16 runs) |
|--------------|------------|
| Reasoning On | 87.5 |
### AIME 2025
| Reasoning Mode | pass@1 (avg. over 16 runs) |
|--------------|------------|
| Reasoning On | 82.71 |
### GPQA
| Reasoning Mode | pass@1 (avg. over 4 runs) |
|--------------|------------|
| Reasoning On | 71.97 |
### LiveCodeBench 24.10-25.02
| Reasoning Mode | pass@1 (avg. over 4 runs) |
|--------------|------------|
| Reasoning On | 73.58 |
### BFCL v3
| Reasoning Mode | pass@1 (avg. over 2 runs) |
|--------------|------------|
| Reasoning On | 71.75 |
### IFEval
| Reasoning Mode | Strict:Instruction |
|--------------|------------|
| Reasoning On | 88.61 |
### ArenaHard
| Reasoning Mode | pass@1 (avg. over 1 runs) |
|--------------|------------|
| Reasoning On | 92.0 |
### Humanity's Last Exam (Text-Only Subset)
| Reasoning Mode | pass@1 (avg. over 1 runs) |
|--------------|------------|
| Reasoning On | 7.64 |
### MMLU Pro (CoT)
| Reasoning Mode | pass@1 (avg. over 1 runs) |
|--------------|------------|
| Reasoning On | 79.53 |
All evaluations were done using the [NeMo-Skills](https://github.com/NVIDIA/NeMo-Skills) repository.
## Inference:
**Engine:**
- Transformers
**Test Hardware:**
- 2x NVIDIA H100-80GB
- 2x NVIDIA A100-80GB GPUs
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](/EXPLAINABILITY.md), [Bias](/BIAS.md), [Safety & Security](/SAFETY&SECURITY.md), and [Privacy](/PRIVACY.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Citation
```
@misc{bercovich2025llamanemotronefficientreasoningmodels,
title={Llama-Nemotron: Efficient Reasoning Models},
author={Akhiad Bercovich and Itay Levy and Izik Golan and Mohammad Dabbah and Ran El-Yaniv and Omri Puny and Ido Galil and Zach Moshe and Tomer Ronen and Najeeb Nabwani and Ido Shahaf and Oren Tropp and Ehud Karpas and Ran Zilberstein and Jiaqi Zeng and Soumye Singhal and Alexander Bukharin and Yian Zhang and Tugrul Konuk and Gerald Shen and Ameya Sunil Mahabaleshwarkar and Bilal Kartal and Yoshi Suhara and Olivier Delalleau and Zijia Chen and Zhilin Wang and David Mosallanezhad and Adi Renduchintala and Haifeng Qian and Dima Rekesh and Fei Jia and Somshubra Majumdar and Vahid Noroozi and Wasi Uddin Ahmad and Sean Narenthiran and Aleksander Ficek and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Igor Gitman and Ivan Moshkov and Wei Du and Shubham Toshniwal and George Armstrong and Branislav Kisacanin and Matvei Novikov and Daria Gitman and Evelina Bakhturina and Jane Polak Scowcroft and John Kamalu and Dan Su and Kezhi Kong and Markus Kliegl and Rabeeh Karimi and Ying Lin and Sanjeev Satheesh and Jupinder Parmar and Pritam Gundecha and Brandon Norick and Joseph Jennings and Shrimai Prabhumoye and Syeda Nahida Akter and Mostofa Patwary and Abhinav Khattar and Deepak Narayanan and Roger Waleffe and Jimmy Zhang and Bor-Yiing Su and Guyue Huang and Terry Kong and Parth Chadha and Sahil Jain and Christine Harvey and Elad Segal and Jining Huang and Sergey Kashirsky and Robert McQueen and Izzy Putterman and George Lam and Arun Venkatesan and Sherry Wu and Vinh Nguyen and Manoj Kilaru and Andrew Wang and Anna Warno and Abhilash Somasamudramath and Sandip Bhaskar and Maka Dong and Nave Assaf and Shahar Mor and Omer Ullman Argov and Scot Junkin and Oleksandr Romanenko and Pedro Larroy and Monika Katariya and Marco Rovinelli and Viji Balas and Nicholas Edelman and Anahita Bhiwandiwalla and Muthu Subramaniam and Smita Ithape and Karthik Ramamoorthy and Yuting Wu and Suguna Varshini Velury and Omri Almog and Joyjit Daw and Denys Fridman and Erick Galinkin and Michael Evans and Katherine Luna and Leon Derczynski and Nikki Pope and Eileen Long and Seth Schneider and Guillermo Siman and Tomasz Grzegorzek and Pablo Ribalta and Monika Katariya and Joey Conway and Trisha Saar and Ann Guan and Krzysztof Pawelec and Shyamala Prayaga and Oleksii Kuchaiev and Boris Ginsburg and Oluwatobi Olabiyi and Kari Briski and Jonathan Cohen and Bryan Catanzaro and Jonah Alben and Yonatan Geifman and Eric Chung and Chris Alexiuk},
year={2025},
eprint={2505.00949},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.00949},
}
```
## Bias
|Field:|Response:|
|:---:|:---:|
|Participation considerations from adversely impacted groups (protected classes) in model design and testing:|None|
|Measures taken to mitigate against unwanted bias:|None|
## Explainability
| Field: | Response: |
| :---- | :---- |
| Intended Application(s) & Domain(s): | Text generation, reasoning, summarization, and question answering. |
| Model Type: | Text-to-text transformer |
| Intended Users: | This model is intended for developers, researchers, and customers building/utilizing LLMs, while balancing accuracy and efficiency. |
| Output: | Text String(s) |
| Describe how the model works: | Generates text by predicting the next word or token based on the context provided in the input sequence using multiple self-attention layers. |
| Technical Limitations: | The model was trained on data that contains toxic language, unsafe content, and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive. The model demonstrates weakness to alignment-breaking attacks. Users are advised to deploy language model guardrails alongside this model to prevent potentially harmful outputs. The Model may generate answers that are inaccurate, omit key information, or include irrelevant or redundant text. |
| Verified to have met prescribed quality standards? | Yes |
| Performance Metrics: | Accuracy, Throughput, and user-side throughput |
| Potential Known Risks: | The model was optimized explicitly for instruction following and as such is susceptible to prompt injection and jailbreaking in various forms as a result of its instruction tuning. The model should be paired with additional rails or system filtering to limit exposure to instructions from malicious sources -- either directly or indirectly by retrieval (e.g. via visiting a website) -- as they may yield outputs that can lead to harmful, system-level outcomes up to and including remote code execution in agentic systems when effective security controls including guardrails are not in place.The model was trained on data that contains toxic language and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive. Model output should be appropriately escaped before viewing or other processing.|
| End User License Agreement: | The trial service is governed by the [NVIDIA API Trial Terms of Service](https://assets.ngc.nvidia.com/products/api-catalog/legal/NVIDIA%20API%20Trial%20Terms%20of%20Service.pdf); and the use of this model is governed by the [NVIDIA Open Model License.](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) Additional Information: [Llama 3.3 Community License Agreement](https://www.llama.com/llama3_3/license/). Built with Llama.|
## Privacy
|Field:|Response:|
|:---:|:---:|
|Generatable or Reverse engineerable personally-identifiable information?|None|
|Was consent obtained for any personal data used?|None Known|
|Personal data used to create this model?|None Known|
|How often is dataset reviewed?|Before Release|
|Is there provenance for all datasets used in training?|Yes|
|Does data labeling (annotation, metadata) comply with privacy laws?|Yes|
|Applicable NVIDIA Privacy Policy|https://www.nvidia.com/en-us/about-nvidia/privacy-policy/|
## Safety & Security
|Field:|Response:|
|:---:|:---:|
|Model Application(s):|Chat, Instruction Following, Chatbot Development, Code Generation, Reasoning|
|Describe life critical application (if present):|None Known (please see referenced Known Risks in the Explainability subcard).|
|Use Case Restrictions:|The trial service is governed by the [NVIDIA API Trial Terms of Service](https://assets.ngc.nvidia.com/products/api-catalog/legal/NVIDIA%20API%20Trial%20Terms%20of%20Service.pdf); and the use of this model is governed by the [NVIDIA Open Model License.](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/) Additional Information: [Llama 3.3 Community License Agreement](https://www.llama.com/llama3_3/license/). Built with Llama.
## Prototype
```python
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$NVIDIA_API_KEY"
)
completion = client.chat.completions.create(
model="",
messages=[{"role":"user","content":""}],
temperature=,
top_p=,
max_tokens=,
frequency_penalty=,
presence_penalty=,
stream=NaN
)
print(completion.choices[0].message)
```
```javascript
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: '$NVIDIA_API_KEY',
baseURL: 'https://integrate.api.nvidia.com/v1',
})
async function main() {
const completion = await openai.chat.completions.create({
model: "",
messages: [{"role":"user","content":""}],
temperature: ,
top_p: ,
max_tokens: ,
frequency_penalty: ,
presence_penalty: ,
stream: ,
})
process.stdout.write(completion.choices[0]?.message?.content);
}
main();
```
```bash
curl https://integrate.api.nvidia.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $NVIDIA_API_KEY" \
-d '{
"model": "",
"messages": [{"role":"user","content":""}],
"temperature": ,
"top_p": ,
"max_tokens": ,
"frequency_penalty": ,
"presence_penalty": ,
"stream":
}'
```