Publisher
Use Case
NIM Type
Sorting by Most Recent

microsoft /
phi-3.5-vision-instructCutting-edge open multimodal model exceling in high-quality reasoning from images.

microsoft /
florence-2Vision foundation model capable of performing diverse computer vision and vision language tasks.

nvidia /
nvclipNvClip generates vector embeddings for the given image or text.

microsoft /
phi-3-vision-128k-instructCutting-edge open multimodal model exceling in high-quality reasoning from images.
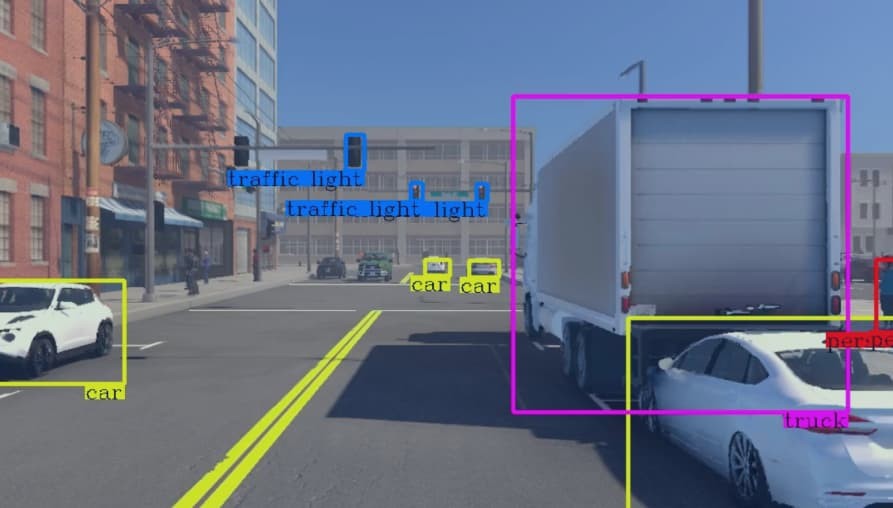
microsoft /
kosmos-2Groundbreaking multimodal model designed to understand and reason about visual elements in images.

google /
deplotOne-shot visual language understanding model that translates images of plots into tables.

adept /
fuyu-8bMulti-modal model for a wide range of tasks, including image understanding and language generation.