
Ingest massive volumes of live or archived videos and extract insights for summarization and interactive Q&A
The NVIDIA AI Blueprint for Video Search and Summarization (VSS) makes it easy to start building and customizing video analytics AI agents. These insightful, accurate, and interactive agents are powered by generative AI, vision language models (VLMs), large language models (LLMs), and NVIDIA NIM™ Microservices—helping a variety of industries make better decisions, faster. They can be given tasks through natural language and perform complex operations like video summarization and visual question-answering, unlocking entirely new application possibilities.
Test the VSS blueprint on the cloud with Launchable, a set of pre-configured sandbox instances that let you quickly try the blueprint without having to bring your own compute infrastructure.
The following NIM microservices are used in this blueprint:
The core video search and summarization blueprint pipeline supports the following hardware:
The following configurations have been validated as minimal, local deployments.
NVIDIA AI Blueprints are customizable agentic workflow examples that include NIM microservices, reference code, documentation, and docker compose for deployment. This blueprint gives you a reference architecture to deploy a visual agent that can quickly generate insights from stored and streamed video through a scalable video ingestion pipeline, VLMs, and hybrid-RAG modules.
VSS contains multiple agent workflows, which are end-to-end use cases which define how the VSS Agent processes requests and coordinates between microservices. The blueprint example demonstrates the video summarization agent workflow.
Additional workflows include:
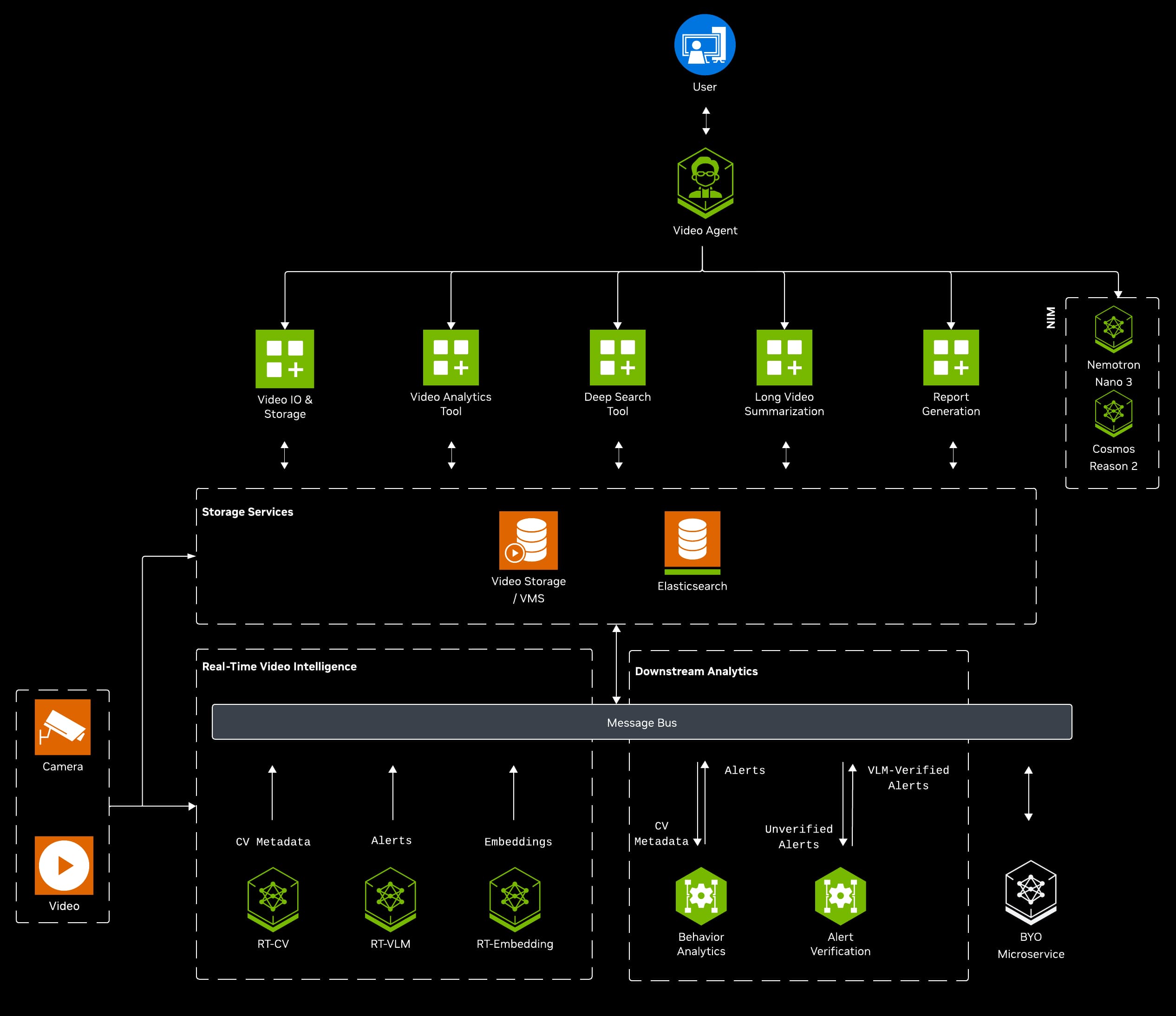
VSS is broken down into 3 major areas of video processing and analysis:
The user selects an example video and prompt to guide the agent in generating a detailed summary. The agent splits the input video into smaller segments that are processed by a VLM (The preview uses OpenAI's GPT4o). These segments are processed in parallel by the VLM pipeline to produce detailed captions describing the events of each chunk in a scalable and efficient manner. The agent recursively summarizes the dense captions using an LLM, generating a final summary for the entire video once all chunk captions are processed.
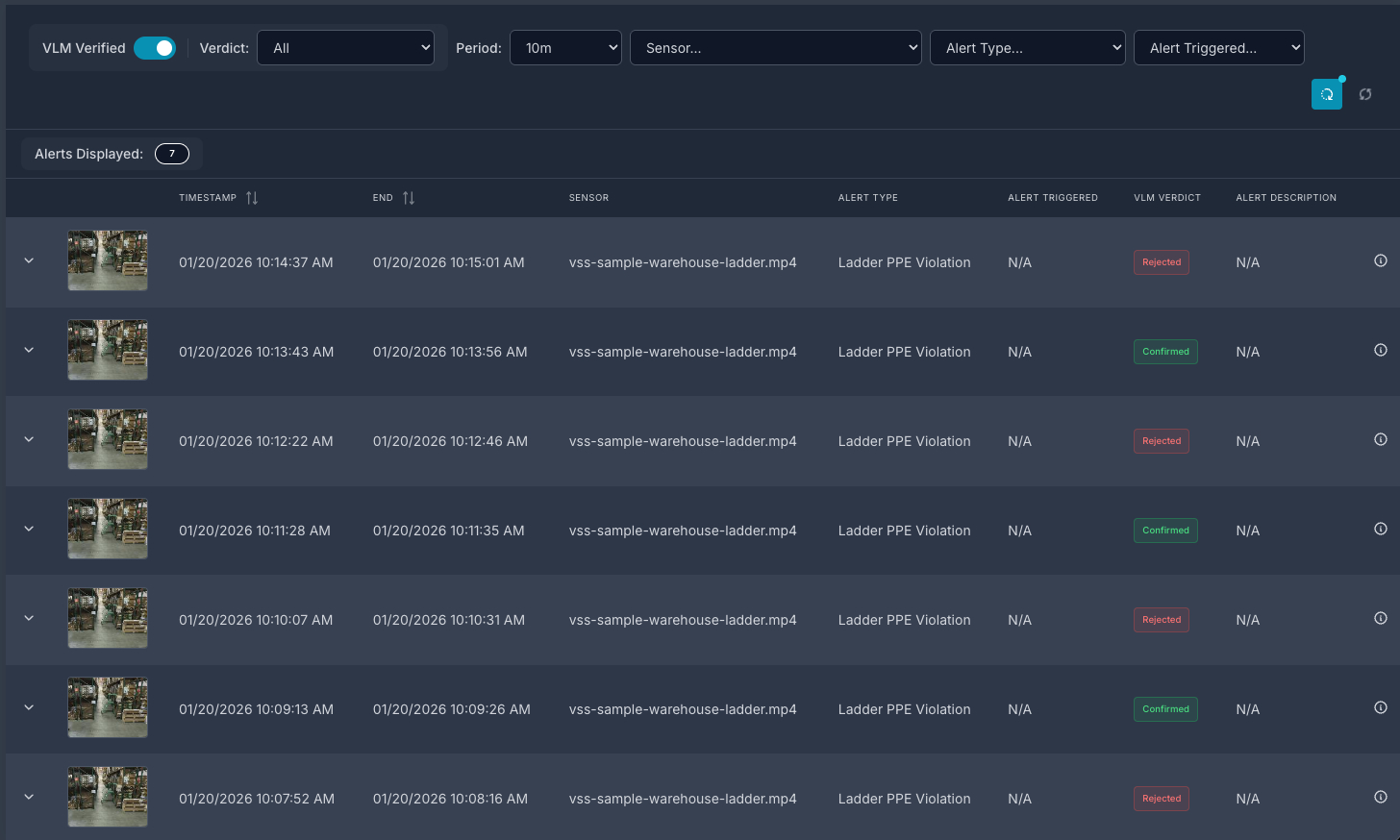
We also provide examples to also demonstrate the computer vision pipeline with object tracking as well as audio support.
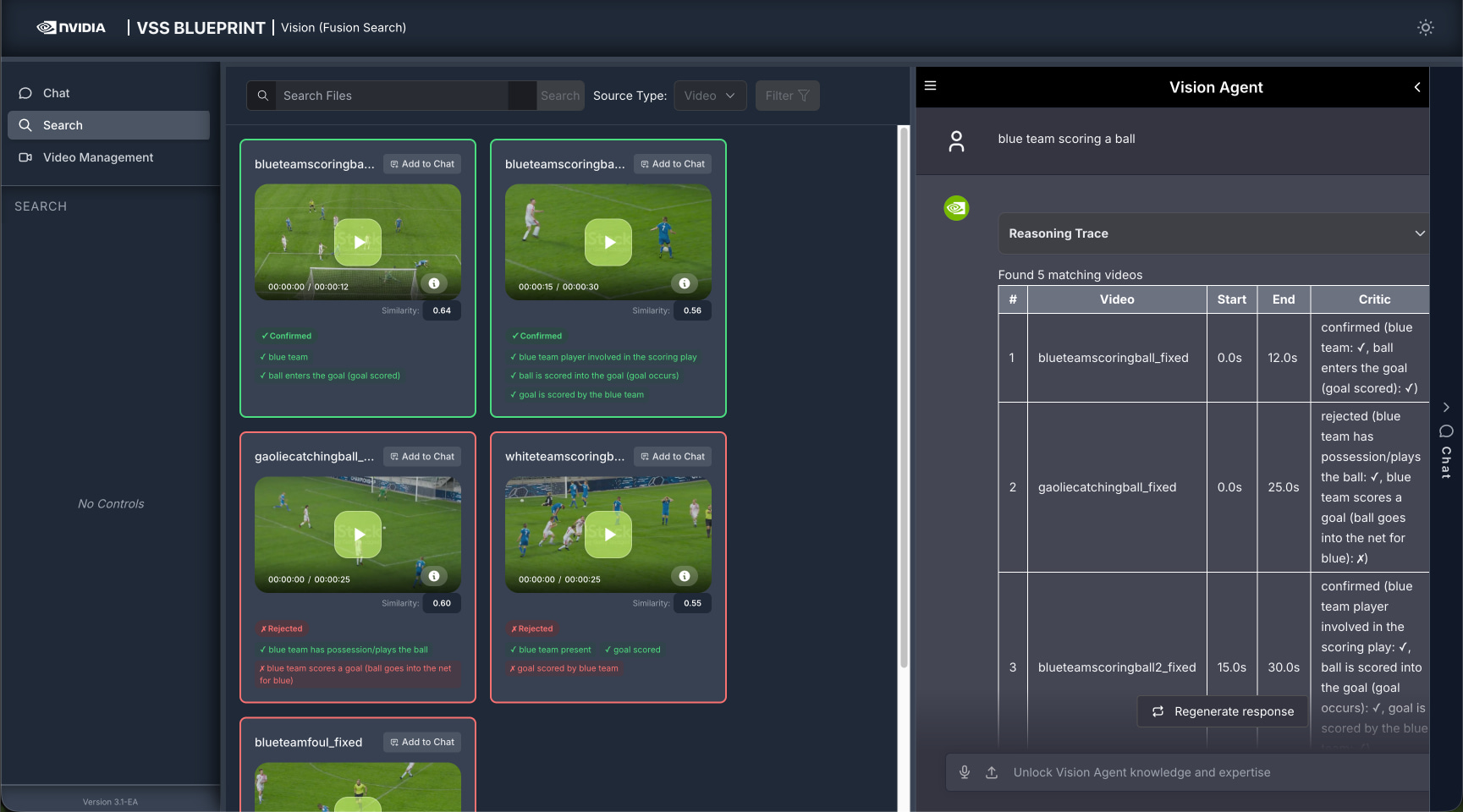
Additionally, these captions are stored in vector and graph databases to power the Q&A feature of this blueprint, allowing the user to ask any open-ended questions about the video.
Use of the models in this blueprint is governed by the NVIDIA AI Foundation Models Community License.
GOVERNING TERMS: This preview is governed by the NVIDIA API Trial Terms of Service.
For the model that includes a Llama3.1 model: Llama 3.1 Community License Agreement, Built with Llama.
For the NVIDIA Retrieval QA Llama 3.2 1B Embedding v2 and NVIDIA Retrieval QA Llama 3.2 1B Reranking v2: Llama 3.2 Community License Agreement, Built with Llama.
For https://github.com/google-research/big_vision/blob/main/LICENSE and https://github.com/01-ai/Yi/blob/main/LICENSE: Apache 2.0 license.