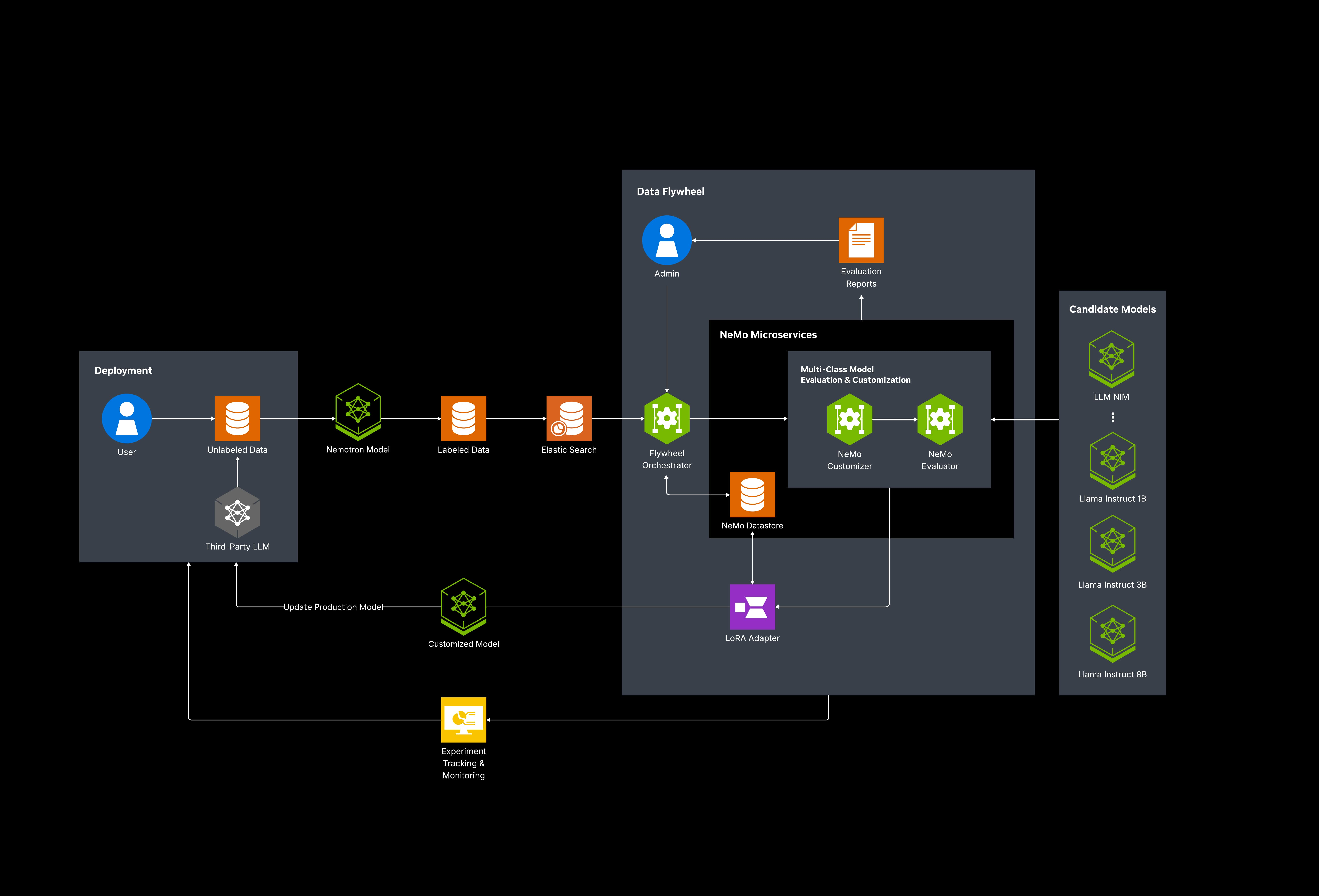
The AI Model Distillation for Financial Data developer example provides a workflow for creating, evaluating, and deploying high-performance, domain-specific models in financial services. Built with NVIDIA Nemotron, NVIDIA NeMo and NVIDIA NIM, it enables continuous distillation, fine-tuning, and evaluation on real financial data, maintaining accuracy while reducing compute costs.
With a self-reinforcing data flywheel, these models are iteratively distilled and domain-adapted on production datasets, enabling rapid backtesting, strategy evaluation, and accelerated experimentation in capital markets. Its modular, scalable architecture integrates seamlessly with existing workflows— whether on-prem, in hybrid clouds, or at the edge—giving developers a hands-on blueprint for building domain-adapted AI solutions at scale.
Key Benefits
- High-Accuracy, Domain-Specific Models: Distills large language models into smaller, domain-tuned versions that deliver equivalent accuracy on proprietary financial tasks—driving precision in alpha research, risk analysis, and strategy evaluation.
- Reduced Latency and Cost: Deploys lightweight NIM microservices optimized for throughput and efficiency—reducing GPU demand, inference cost, and energy use without compromising performance.
- Accelerated Backtesting and Strategy Evaluation: Enables rapid iteration and evaluation of trading signals, maintaining model accuracy as market conditions and data sources evolve.
- Scalable, Observed Experimentation: Facilitates model evaluation with built-in observability and experiment tracking through Kubernetes, Weights & Biases or MLflow.
- Easy Integration and Deployment: Adopts a modular architecture for effortless integration with existing financial AI workflows—supporting on-premises, hybrid cloud, and edge deployments.
- Flexibility: Developers can select any supported model for their workflow, including NVIDIA Nemotron family of open models, for frontier AI development among the most open in the AI ecosystem based on the permissibility of the model licenses, data transparency, and availability of technical details.
Architecture Diagram
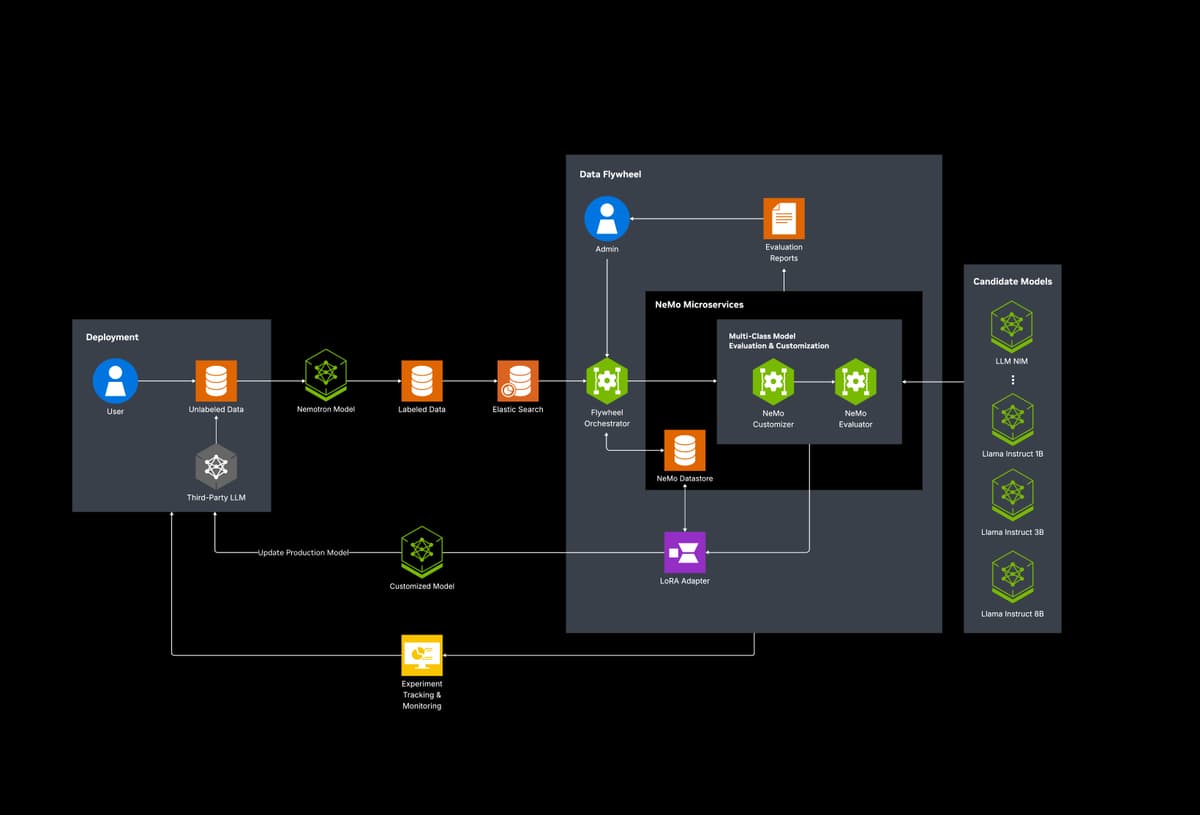
What’s Included in the Blueprint
Key Features
- Automated and Scalable Model Experimentation: Scales through Kubernetes to dynamically launch candidate NIM from a model registry for LoRA-based fine-tuning experiments, supporting model evaluation with integrated tracking using Weights & Biases or MLflow.
- Edge-Ready Deployment: Smaller models make deployment feasible in power–and compute–constrained environments.
- Fine-Tuning with NVIDIA NeMo Customizer and Evaluations through NeMo Evaluator: Runs parameter-efficient fine-tuning on models using domain-specific datasets through LoRA-SFT fine-tuning and evaluates on task-specific metrics such as F1-score.
- Easy Deployment and Enterprise-Grade Compliance: Simplifies deployment and management of the Data Flywheel Blueprint on Kubernetes setup with a unified, configurable Helm chart in on-prem, Docker-native, or hybrid environments.
- Developer Productivity: Ready-to-use reference notebooks, configuration files, and GitLab repository for rapid iteration.
Minimum System Requirements
Hardware Requirements
- 2x (NVIDIA A100/H100/H200/B200 GPUs)
- Minimum Memory: 1GB (512MB reserved for Elasticsearch)
- Storage: Varies based on log volume and model size (at least 200GB to run the Blueprint)
- Network: Ports 8000 (API), 9200 (Elasticsearch), 27017 (MongoDB), 6379 (Redis), 5000 (MLFlow)
OS Requirements
Software Dependencies
- Elasticsearch 8.12.2
- MongoDB 7.0
- Redis 7.2
- FastAPI (API server)
- Celery (task processing)
- Python 3.12
- MLflow 2.22.0
- Wandb 0.22.3
- One of the following orchestration tools:
- Docker Engine & Docker Compose (for local development and simple, single-host environments)
- Kubernetes (>=1.25) and Helm (>=3.8) (for production and multi-node clusters)
Software Used in This Blueprint
NVIDIA Technology
- NIM Microservices:
- llama-3.3-70b-instruct
- llama-3.3-nemotron-super-49b-v1
- llama-3.2-1b-instruct
- llama-3.2-3b-instruct
- llama-3.1-8b-instruct
- NeMo Microservices:
- NeMo Customizer: Model finetuning
- NeMo Evaluator: Model and workflow evaluation
- Datastore: Stores datasets, evaluation results, fine-tuning artifacts
- Deployment Manager: Deploys and experiments with candidate models
- Entity Store: Unified data model and registry
- NIM Proxy: Routes inference across multiple models
3rd Party Software
- Elasticsearch
- MongoDB
- Redis
- FastAPI
- Celery
- MLflow
- Wandb
Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility, and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure the models meet requirements for the relevant industry and use case and address unforeseen product misuse. Please report security vulnerabilities or NVIDIA AI concerns here.
License
Use of the models in this blueprint is governed by the NVIDIA AI Foundation Models Community License.
Terms of Use
Use of the Jupyter notebook and scripts is governed by the Apache 2.0 License. Use of the Nemo Evaluator and Customizer microservices is governed by the NVIDIA Software License Agreement and Product-Specific Terms for NVIDIA AI Products. Use of the Llama-3.1-8B-Instruct, Llama-3.1-70B-Instruct, Llama-3.2-1B-Instruct, and Llama 3.3-70B-Instruct models is governed by the NVIDIA Community Model License. Use of the Llama-3.3-Nemotron-Super-49B-v1 and Llama-3.2-3B-Instruct models is governed by the NVIDIA Open Model License Agreement.
Llama 3.1 Community License Agreement for Llama-3.1-8B-Instruct and Llama-3.1-70B-Instruct. Llama 3.2 Community License Agreement for Llama-3.2-1B-Instruct and Llama-3.2-3B-Instruct. Llama 3.3 Community License Agreement for Llama 3.3-70B-Instruct and Llama-3.3-Nemotron-Super-49B-v1. Built with Llama.