
Sensor-captured radio enables real-time awareness, AI-driven analytics for actionable, searchable insights.
Traditional retrieval-augmented generation (RAG) systems rely on static data ingested in batches, which limits their ability to support time-critical use cases like emergency response or live monitoring. These situations require immediate access to dynamic data sources such as sensor feeds or radio signals.
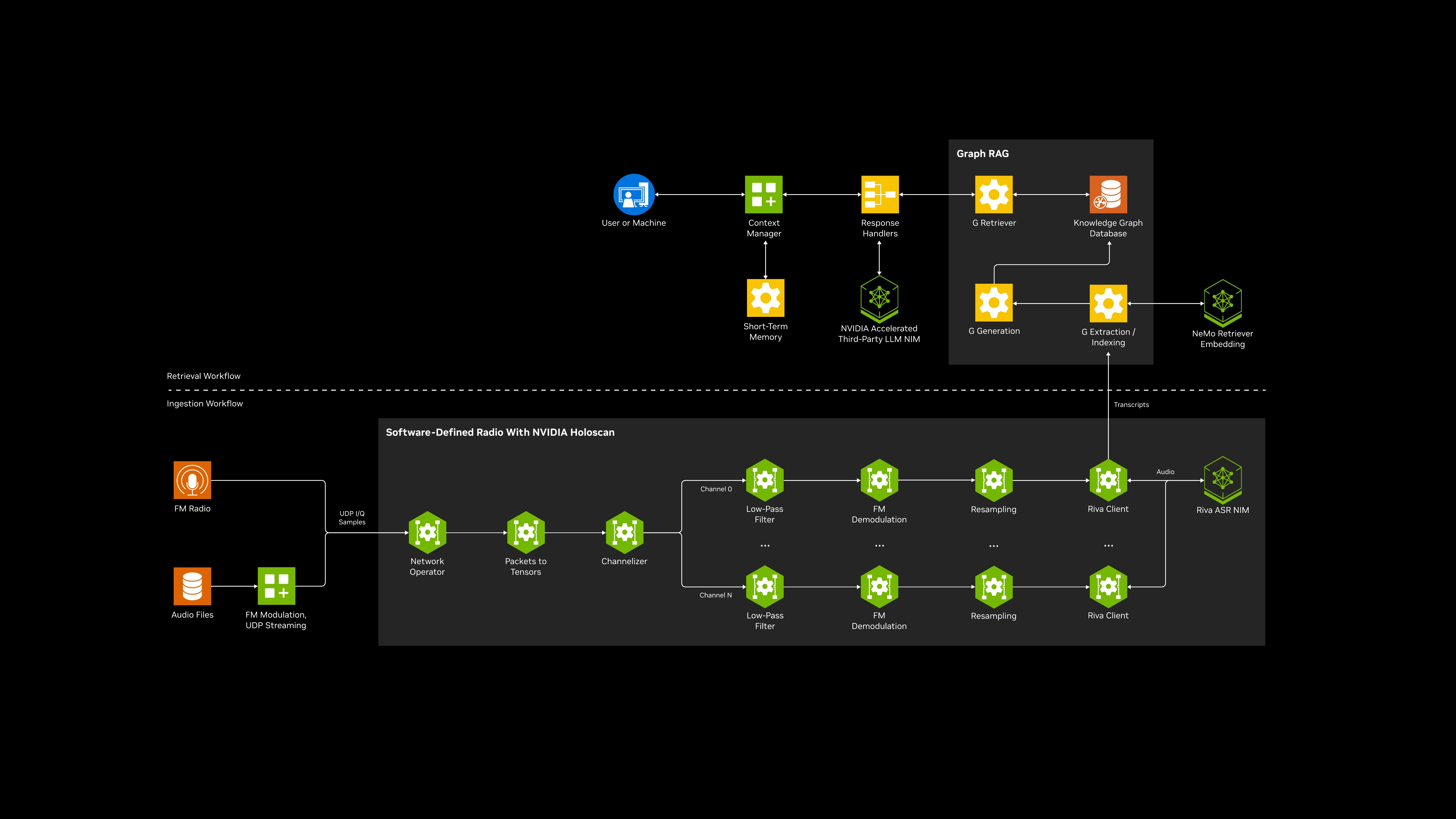
The Streaming Data to RAG developer example solves this by enabling RAG systems to process live data streams in real-time. It features a GPU-accelerated software-defined radio (SDR) pipeline that continuously captures radio frequency (RF) signals, transcribes them into searchable text, embeds, and indexes them in real time. This live data is then fed to a large language model (LLM), allowing context-aware queries over dynamic streams.
Designed for scalability across edge and cloud environments, this reference example unlocks real-time situational awareness for use cases like spectrum monitoring, intelligence gathering, and other mission-critical applications—while retaining RAG’s strengths in delivering accurate, relevant results.
To learn more about how this blueprint is applied in real-world implementations, check out the detailed tech blogs from Deepwave and DataRobot.
These GPUs ensure sufficient memory and compute resources for advanced AI, visualization, and generative workloads.
NVIDIA Technology
3rd Party Software
NVIDIA believes Trustworthy AI is a shared responsibility, and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure the models meet requirements for the relevant industry and use case and address unforeseen product misuse. Please report security vulnerabilities or NVIDIA AI concerns here.
Use of the models in this blueprint is governed by the NVIDIA AI Foundation Models Community License.
The software and materials are governed by the NVIDIA Software License Agreement and the Product-Specific Terms for AI Products; except for NVIDIA Nemotron Nano 9B v2, which is governed by the the NVIDIA Open Model License; the other models, which are governed by the NVIDIA Community Model License; the NVIDIA NeMo Agent Toolkit UI, which is governed by the MIT License; the NVIDIA Holoscan SDK and the NVIDIA Context Aware RAG, which are governed by the Apache 2.0 License; and the audio files, which are licensed under the Creative Commons Attribution 4.0 International License (CC BY 4.0).
For llama-3.2-nv-embedqa-1b-v2 and llama-3.2-nv-rerankqa-1b-v2, the Llama 3.2 Community License Agreement. Built with Llama.