⌘KCtrl+K

Vision language model that excels in understanding the physical world using structured reasoning on videos or images.
NVIDIA Cosmos Reason 2 is an open, customizable, 8B-parameter reasoning vision language model (VLM) for physical AI and robotics that enables robots and vision AI agents to reason like humans, using prior knowledge, physics understanding and common sense to understand and act in the real world. This model understands space, time, and fundamental physics, and can serve as a planning model to reason what steps an embodied agent might take next.
New features with Cosmos Reason 2:
Use cases:
Explore the Cosmos Cookbook, a technical guide that delivers end-to-end workflows, implementation recipes, and detailed examples for building, fine-tuning, and deploying Cosmos Reason in production-ready environments.
The model is ready for commercial use.
Model Developer: NVIDIA
The Cosmos-Reason2 includes the following model:
GOVERNING TERMS: This trial service is governed by the NVIDIA API Trial Terms of Service. Use of the model is governed by the NVIDIA Open Model License Agreement.Additional Information: Apache License 2.0
Models are commercially usable.
You are free to create and distribute Derivative Models. NVIDIA does not claim ownership to any outputs generated using the Models or Derivative Models.
Important Note: If you bypass, disable, reduce the efficacy of, or circumvent any technical limitation, safety guardrail or associated safety guardrail hyperparameter, encryption, security, digital rights management, or authentication mechanism (collectively “Guardrail”) contained in the Model without a substantially similar Guardrail appropriate for your use case, your rights under this Agreement NVIDIA Open Model License Agreement will automatically terminate.
Global
Physical AI: Space, time, fundamental physics understanding and embodied reasoning, encompassing robotics, and autonomous vehicles (AV).
Build.NVIDIA.com 01/05/2026 via link
Huggingface 12/18/2025 via link
Downloadable NIM - Cosmos Reason2 2B 01/21/2026 via link
Downloadable NIM - Cosmos Reason2 8B 01/21/2026 via link
Architecture Type: A Multi-modal LLM consists of a Vision Transformer (ViT) for vision encoder and a Dense Transformer model for LLM. Network Architecture: Qwen3-VL-8B-Instruct.
Cosmos-Reason2-8B is post-trained based on Qwen3-VL-8B-Instruct and follows the same model architecture.
Number of model parameters:
Cosmos-Reason2-8B: 8,767,123,696
Input Type(s): Text+Video/Image
Input Format(s):
Text: String
Video: mp4
Image: jpg
Input Parameters:
Text: One-dimensional (1D)
Video: Three-dimensional (3D)
Image: Two-dimensional (2D)
Other Properties Related to Input:
Use FPS=4 for input video to match the training setup.
Append Answer the question in the following format: <think>\nyour reasoning\n</think>\n\n<answer>\nyour answer\n</answer>. in the system prompt to encourage long chain-of-thought reasoning response.
Output Type(s): Text
Output Format: String
Output Parameters: Text: One-dimensional (1D)
Other Properties Related to Output:
Runtime Engine(s):
Supported Hardware Microarchitecture Compatibility:
Note: We have only tested doing inference with BF16 precision.
Operating System(s):
The integration of foundation and fine-tuned models into AI systems requires additional testing using use-case-specific data to ensure safe and effective deployment. Following the V-model methodology, iterative testing and validation at both unit and system levels are essential to mitigate risks, meet technical and functional requirements, and ensure compliance with safety and ethical standards before deployment.
See Cosmos-Reason2 for details.
Cosmos-Reason2-8B model was trained and evaluated on the same datasets used for Cosmos-Reason1-7B, in addition to the following newly added datasets.
Data Collection Method:
Labeling Method:
The combined datasets span multimodal video, sensor signals, and structured physical-reasoning tasks, providing broad coverage for training world-model reasoning capabilities.
Data Collection Method:
Labeling Method:
The combined datasets span multimodal video, sensor signals, and structured physical-reasoning tasks, providing broad coverage for training world-model reasoning capabilities.
Modality: Video (mp4) and Text
Test Hardware: H100, A100
NOTE
We suggest using fps=4 for the input video and max_tokens=4096 to avoid truncated response.
import transformers
import torch
model_name = "nvidia/Cosmos-Reason2-8B"
model = transformers.Qwen3VLForConditionalGeneration.from_pretrained(
model_name, dtype=torch.float16, device_map="auto", attn_implementation="sdpa"
)
processor: transformers.Qwen3VLProcessor = (
transformers.AutoProcessor.from_pretrained(model_name)
)
video_messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}],
},
{"role": "user", "content": [
{
"type": "video",
"video": "file:///path/to/your/video.mp4",
"fps": 4,
},
{"type": "text", "text": (
"Is it safe to turn right? Answer the question using the following format:\n\n<think>\nYour reasoning.\n</think>\n\nWrite your final answer immediately after the </think> tag."
)
},
]
},
]
# Process inputs
inputs = processor.apply_chat_template(
video_messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
fps=4,
)
inputs = inputs.to(model.device)
# Run inference
generated_ids = model.generate(**inputs, max_new_tokens=4096)
generated_ids_trimmed = [
out_ids[len(in_ids) :]
for in_ids, out_ids in zip(inputs.input_ids, generated_ids, strict=False)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False,
)
This model requires a minimum of 32 GB of GPU memory. Inference latency for a single generation across different NVIDIA GPU platforms will be published shortly.
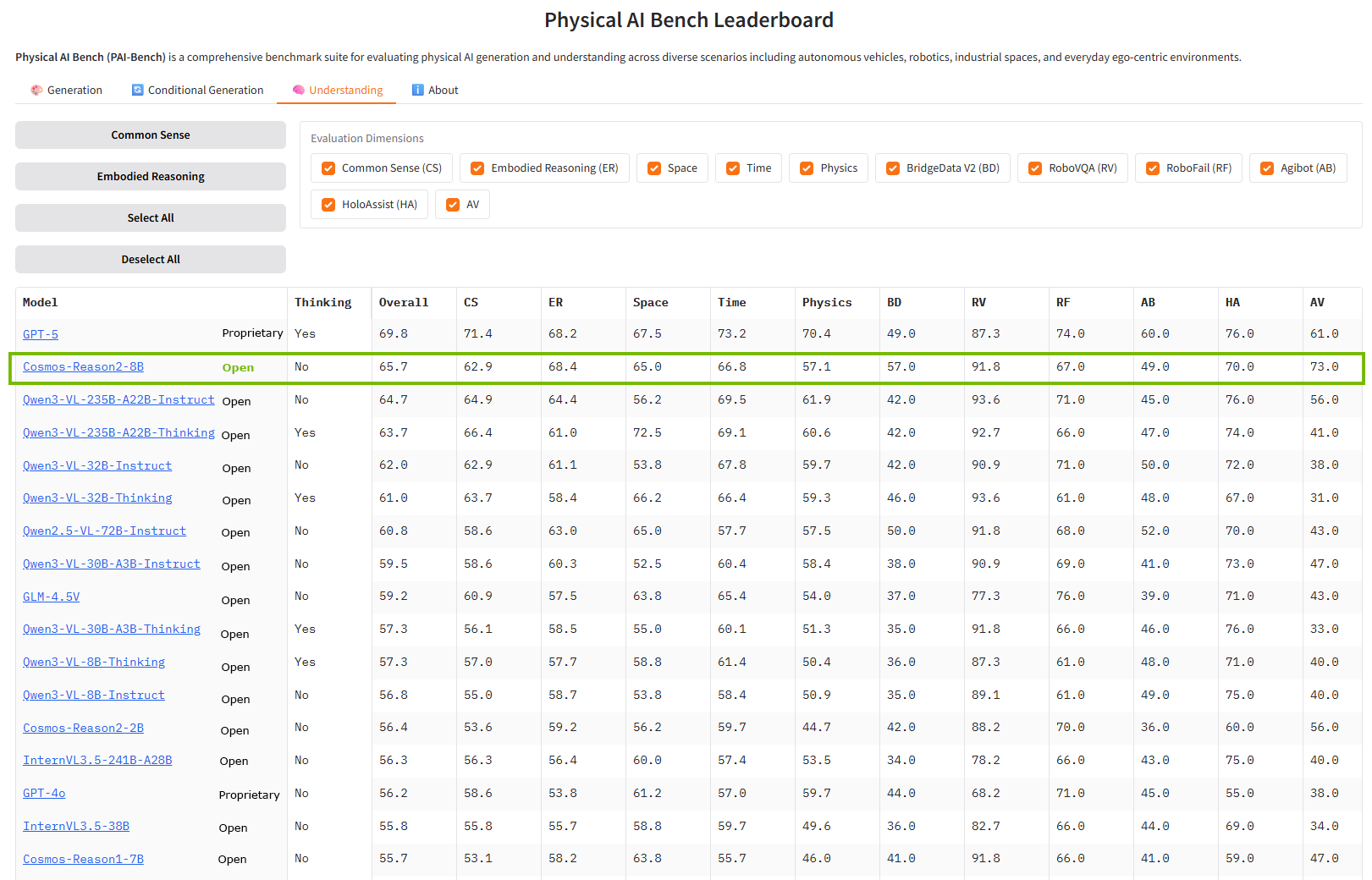
For comparative evaluation, we present benchmark scores using the Physical AI Bench Leaderboard.
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Users are responsible for model inputs and outputs. Users are responsible for ensuring safe integration of this model, including implementing guardrails as well as other safety mechanisms, prior to deployment.
For more detailed information on ethical considerations for this model, please see the subcards of Explainability, Bias, Safety & Security, and Privacy below.
Please report security vulnerabilities or NVIDIA AI Concerns here.
We value you, the datasets, the diversity they represent, and what we have been entrusted with. This model and its associated data have been: