Leverage retrieval-augmented generation to ground large language models in your proprietary data.
Developer examples designed for quick-start AI development in financial services, including artifacts like Docker containers and Jupyter Notebooks, allowing for fast deployment with tools like Docker compose and Brev Launchable.

Automate and scale the discovery, testing, and refinement of trading signals for quantitative research.

Create intelligent embeddings by using transformer architecture on tabular data.
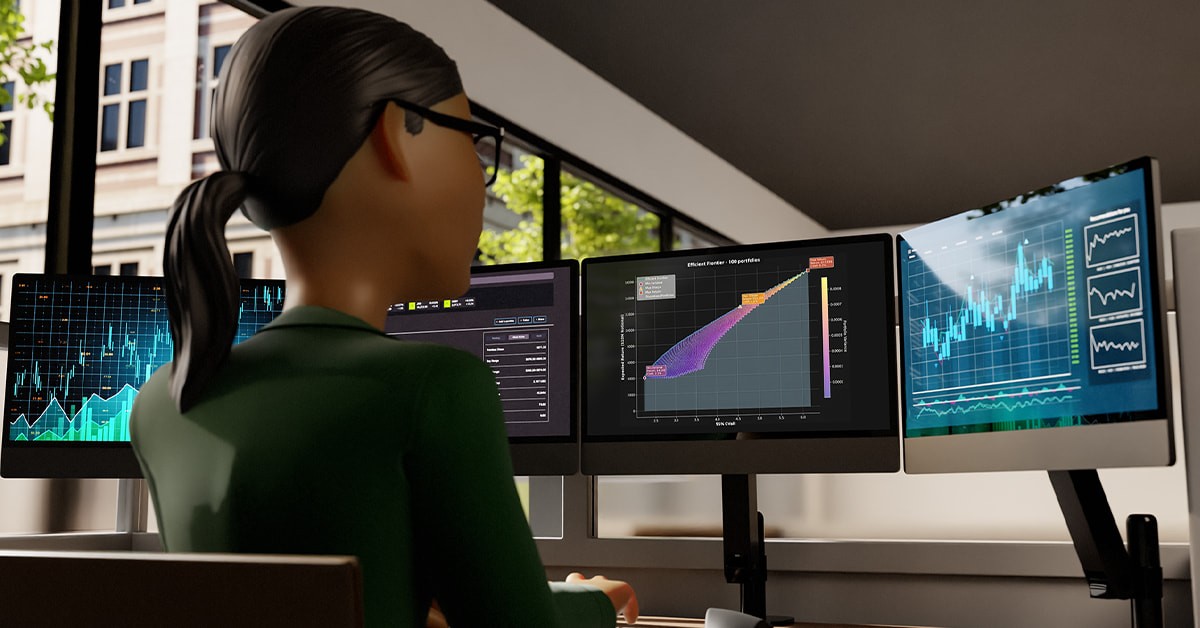
Enable fast, scalable, and real-time portfolio optimization for financial institutions.
Distill and deploy domain-specific AI models from unstructured financial data to generate market signals efficiently—scaling your workflow with the NVIDIA Data Flywheel Blueprint for high-performance, cost-efficient experimentation.

Detect and prevent sophisticated fraudulent activities for financial services with high accuracy.
Comprehensive reference workflows that accelerate application development and deployment, featuring NVIDIA acceleration libraries, APIs, and microservices for AI agents, digital twins, and more.

AI agents that connect, retrieve, and reason on enterprise data—making information accessible, actionable, and intelligent.

Power fast, accurate semantic search across multimodal enterprise data with NVIDIA’s RAG Blueprint—built on NeMo Retriever and Nemotron models—to connect your agents to trusted, authoritative sources of knowledge.

Ingest massive volumes of live or archived videos and extract insights for summarization and interactive Q&A