⌘KCtrl+K

A context‑aware safety model that applies reasoning to enforce domain‑specific policies.

An AI-powered, multi-agent system designed to optimize warehouse operations through intelligent automation, real-time monitoring, and natural language interaction.

A GenAI system that enhances and localizes product catalogs with rich text content and imagery.

Vision language model that excels in understanding the physical world using structured reasoning on videos or images.

Model for object detection, fine-tuned to detect charts, tables, and titles in documents.

Open, efficient MoE model with 1M context, excelling in coding, reasoning, instruction following, tool calling, and more

Translation model in 12 languages with few-shots example prompts capability.
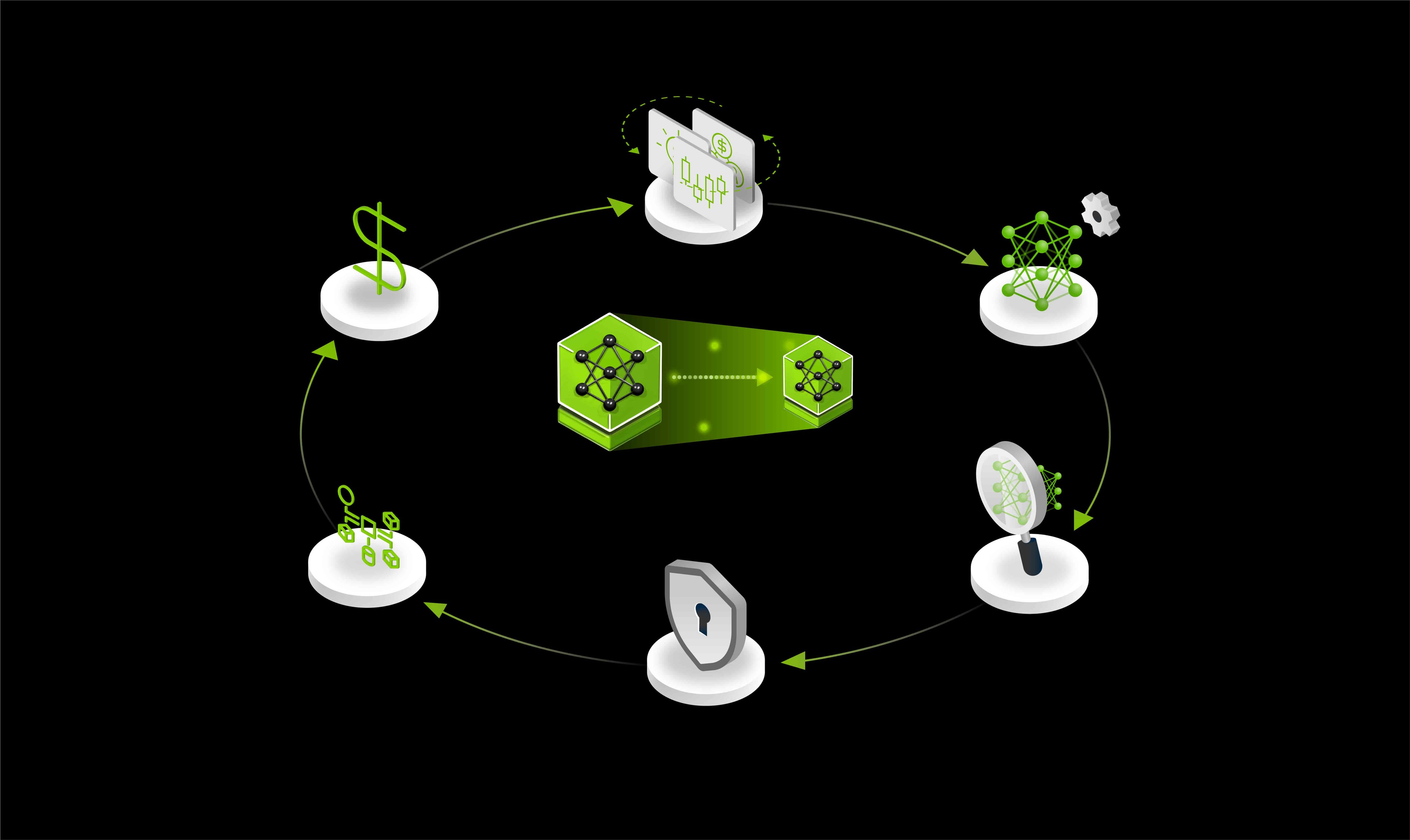
Distill and deploy domain-specific AI models from unstructured financial data to generate market signals efficiently—scaling your workflow with the NVIDIA Data Flywheel Blueprint for high-performance, cost-efficient experimentation.
Enable fast, scalable, and real-time portfolio optimization for financial institutions.

StreamPETR offers efficient 3D object detection for autonomous driving by propagating sparse object queries temporally.

Accelerate post-training of end-to-end autonomous vehicle stacks with vector search and retrieval for large video datasets.

Build advanced AI agents for providers and patients using this developer example powered by NeMo Microservices, NVIDIA Nemotron, Riva ASR and TTS, and NVIDIA LLM NIM

Cutting-edge vision-language model exceling in retrieving text and metadata from images.

Nemotron Nano 12B v2 VL enables multi-image and video understanding, along with visual Q&A and summarization capabilities.

Leading multilingual content safety model for enhancing the safety and moderation capabilities of LLMs

Record-setting accuracy and performance for Mandarin Taiwanese English transcriptions.

Multilingual, cross-lingual embedding model for long-document QA retrieval, supporting 26 languages.

Record-setting accuracy and performance for Mandarin English transcriptions.

Accurate and optimized Spanish English transcriptions with punctuation and word timestamps.

Accurate and optimized Vietnamese-English transcriptions with punctuation and word timestamps.

Transform your scene idea into ready-to-use 3D assets using Llama 3.1 8B, NV SANA, and Microsoft TRELLIS

Elevate Shopping Experiences Online and In Stores.

High‑efficiency LLM with hybrid Transformer‑Mamba design, excelling in reasoning and agentic tasks.

Reasoning vision language model (VLM) for physical AI and robotics.

Powerful OCR model for fast, accurate real-world image text extraction, layout, and structure analysis.

Accurate and optimized English transcriptions with punctuation and word timestamps

Sensor-captured radio enables real-time awareness, AI-driven analytics for actionable, searchable insights.
High efficiency model with leading accuracy for reasoning, tool calling, chat, and instruction following.

Multilingual, cross-lingual embedding model for long-document QA retrieval, supporting 26 languages.
Powerful OCR model for fast, accurate real-world image text extraction, layout, and structure analysis.

Generates high-quality numerical embeddings from text inputs.

Rapidly identify and mitigate container security vulnerabilities with generative AI.

Ingest massive volumes of live or archived videos and extract insights for summarization and interactive Q&A

Fine-tuned reranking model for multilingual, cross-lingual text question-answering retrieval, with long context support.

English text embedding model for question-answering retrieval.

This blueprint shows how generative AI and accelerated NIM microservices can design optimized small molecules smarter and faster.


Multilingual and cross-lingual text question-answering retrieval with long context support and optimized data storage efficiency.
This blueprint shows how generative AI and accelerated NIM microservices can design protein binders smarter and faster.

This workflow shows how generative AI can generate DNA sequences that can be translated into proteins for bioengineering.

High efficiency model with leading accuracy for reasoning, tool calling, chat, and instruction following.

End-to-end autonomous driving stack integrating perception, prediction, and planning with sparse scene representations for efficiency and safety.


Improve safety, security, and privacy of AI systems at build, deploy and run stages.

Build a custom enterprise research assistant powered by state-of-the-art models that process and synthesize multimodal data, enabling reasoning, planning, and refinement to generate comprehensive reports.

Create intelligent virtual assistants for customer service across every industry

Superior inference efficiency with highest accuracy for scientific and complex math reasoning, coding, tool calling, and instruction following.

Use the multi-LLM compatible NIM container to deploy a broad range of LLMs from Hugging Face.

Expressive and engaging text-to-speech, generated from a short audio sample.

Power fast, accurate semantic search across multimodal enterprise data with NVIDIA’s RAG Blueprint—built on NeMo Retriever and Nemotron models—to connect your agents to trusted, authoritative sources of knowledge.

Model for object detection, fine-tuned to detect charts, tables, and titles in documents.

Design, test, and optimize a new generation of intelligence manufacturing data centers using digital twins.

Orchestrate AI agents for data flywheel with MLRun and NVIDIA NeMo microservices.

Industry leading jailbreak classification model for protection from adversarial attempts

Multi-modal vision-language model that understands text/img and creates informative responses

Build a data flywheel, with NVIDIA NeMo microservices, that continuously optimizes AI agents for latency and cost — while maintaining accuracy targets.

State-of-the-art open model for reasoning, code, math, and tool calling - suitable for edge agents

Generates physics-aware video world states for physical AI development using text prompts and multiple spatial control inputs derived from real-world data or simulation.
Leading reasoning and agentic AI accuracy model for PC and edge.

Record-setting accuracy and performance for English transcription.

Natural and expressive voices in multiple languages. For voice agents and brand ambassadors.

Enable smooth global interactions in 36 languages.

GPU-accelerated model optimized for providing a probability score that a given passage contains the information to answer a question.

Multimodal question-answer retrieval representing user queries as text and documents as images.

Automate and optimize the configuration of radio access network (RAN) parameters using agentic AI and a large language model (LLM)-driven framework.

Converts streamed audio to facial blendshapes for realtime lipsyncing and facial performances.

Removes unwanted noises from audio improving speech intelligibility.


State-of-the-art accuracy and speed for English transcriptions.

Enhance speech by correcting common audio degradations to create studio quality speech output.

Create high quality images using Flux.1 in ComfyUI, guided by 3D.

Expressive and engaging text-to-speech, generated from a short audio sample.

Investigate, understand, and interpret single cell data in minutes, not days by leveraging RAPIDS-singlecell, powered by NVIDIA RAPIDS

Build advanced AI agents within the biomedical domain using the AI-Q Blueprint and the BioNeMo Virtual Screening Blueprint

Cutting-edge vision-language model exceling in retrieving text and metadata from images.

Detect and prevent sophisticated fraudulent activities for financial services with high accuracy.

Simulate, test, and optimize physical AI and robotic fleets at scale in industrial digital twins before real-world deployment.

The NV-EmbedCode model is a 7B Mistral-based embedding model optimized for code retrieval, supporting text, code, and hybrid queries.

Route LLM requests to the best model for the task at hand.

Generate exponentially large amounts of synthetic motion trajectories for robot manipulation from just a few human demonstrations.

Enhance and modify high-quality compositions using real-time rendering and generative AI output without affecting a hero product asset.

Advanced LLM to generate high-quality, context-aware responses for chatbots and search engines.

NVIDIA DGX Cloud trained multilingual LLM designed for mission critical use cases in regulated industries including financial services, government, heavy industry

A bilingual Hindi-English SLM for on-device inference, tailored specifically for Hindi Language.

This LLM follows instructions, completes requests, and generates creative text.


Easily run essential genomics workflows to save time leveraging Parabricks

Develop AI powered weather analysis and forecasting application visualizing multi-layered geospatial data.

This NVIDIA Omniverse™ Blueprint demonstrates how commercial software vendors can create interactive digital twins.

Automate voice AI agents with NVIDIA NIM microservices and Pipecat.

Transform PDFs into AI podcasts for engaging on-the-go audio content.

High accuracy and optimized performance for transcription in 25 languages

Enable smooth global interactions in 36 languages.

Robust Speech Recognition via Large-Scale Weak Supervision.

Multi-lingual model supporting speech-to-text recognition and translation.

Grounding dino is an open vocabulary zero-shot object detection model.

Leading content safety model for enhancing the safety and moderation capabilities of LLMs

Topic control model to keep conversations focused on approved topics, avoiding inappropriate content.

FourCastNet predicts global atmospheric dynamics of various weather / climate variables.

Estimate gaze angles of a person in a video and redirect to make it frontal.


Generates future frames of a physics-aware world state based on simply an image or short video prompt for physical AI development.

Model for object detection, fine-tuned to detect charts, tables, and titles in documents.

Model for object detection, fine-tuned to detect charts, tables, and titles in documents.

Model for object detection, fine-tuned to detect charts, tables, and titles in documents.

Multi-modal vision-language model that understands text/img/video and creates informative responses

GPU-accelerated model optimized for providing a probability score that a given passage contains the information to answer a question.

Verify compatibility of OpenUSD assets with instant RTX render and rule-based validation.

Leaderboard topping reward model supporting RLHF for better alignment with human preferences.

Visual Changenet detects pixel-level change maps between two images and outputs a semantic change segmentation mask

EfficientDet-based object detection network to detect 100 specific retail objects from an input video.

Optimized SLM for on-device inference and fine-tuned for roleplay, RAG and function calling

State-of-the-art small language model delivering superior accuracy for chatbot, virtual assistants, and content generation.






